
📊 Full opportunity report: China Sphere Capability Gap, Q2 2026 Update: Five Labs, Five Strategies, One Narrowing Frontier on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
In April 2026, five Chinese AI labs released frontier-tier models within four weeks, signaling a significant shift in China’s AI capabilities. While the US still leads in top-tier tasks, China advances in cost, licensing, and scale, redefining the global AI race.
In April 2026, five Chinese AI labs released frontier-tier models within a four-week window, signaling a coordinated and rapid capability expansion that challenges the previous US dominance in high-end AI tasks.
On April 8, Z.ai released GLM-5.1, a 754-billion-parameter model trained entirely on Huawei Ascend hardware, and licensed under MIT, making it highly permissive for redistribution and fine-tuning. This was followed by Moonshot’s Kimi K2.6 on April 20, which demonstrated advanced autonomous coding and agent orchestration capabilities with a 300-agent swarm. Between April 24 and 27, DeepSeek launched V4 Pro and V4 Flash, with the latter offering production-level performance at just $0.14 per million tokens, a price point 5-30 times lower than Western counterparts. Alibaba’s Qwen 3.6 series, including Max-Preview and Plus, also contributed to this wave, with competitive pricing and open-weight licensing. These launches collectively mark a structural shift, establishing a five-lab ecosystem capable of delivering frontier-tier models at substantially lower costs than US labs, though the US still maintains a lead in the most complex tasks and generalization capabilities.
Five labs. One narrowing frontier.
April 2026 was the most consequential month for Chinese frontier AI since DeepSeek R1 in January 2025.
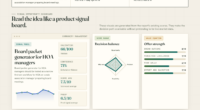
Five Chinese labs shipped frontier-tier models in a four-week window. Kimi K2.6, Qwen 3.6, DeepSeek V4 Pro/Flash, GLM-5.1 (MIT, 754B params on Huawei Ascend), MiniMax M2.7. Cost gap 5–30× cheaper. Top-of-pyramid gap 10 points and narrowing. Multi-model routing is now production architecture.
Top of pyramid still Western. Mid-frontier is now Chinese.
AkitaOnRails benchmark · Rails + RubyLLM + Hotwire + Docker app from fixed prompt · 23 models scored against actual gem source. Tier A: only Kimi K2.6 (87) from China alongside Western trio (Opus 4.7, GPT-5.4 xHigh, GPT-5.5 at 96-97). Tier B is Chinese-dominated.
Different dimensions. Different leaders.
“China has caught up” and “Western frontier still ahead” are both partially right, on different dimensions. The dimensions where China leads are the ones that matter most for production deployment economics.
- Top hard-benchmark scoresOpus 4.7 + GPT-5.4 xHigh tied 97/100. 10-point gap to Chinese top.
- Generalization to unseen tasksDecontaminated benchmarks show clear edge. Where Chinese labs lag most.
- Arena Elo top tierAnthropic 1503 leads Alibaba 1449 by ~3.5%. Narrowing but real.
- Lab count: 4 frontier (Anthropic, OpenAI, Google, xAI)Stable; not growing.
- Cost per M tokensDeepSeek V4 Flash $0.14 vs Opus $15. 5–30× advantage at scale.
- Open-weight licensingGLM-5.1 under MIT. 754B params, no restrictions. Most permissive frontier model.
- Agent orchestration scaleKimi K2.6 · 300-agent swarm. Architecturally distinct, not incremental.
- Sovereign silicon validationGLM-5.1 trained entirely on Huawei Ascend. Export-restriction lever compressed.
- Lab count: 5+ frontierPlus Xiaomi, StepFun in second tier. Growing.
Five labs, five strategies, one narrowing frontier.
Different positioning, different competitive moats, different routing destinations. The Chinese frontier is no longer DeepSeek-plus-Qwen-plus-tail. It’s a five-lab ecosystem with differentiated strategies.
frontier
lineup
orchestration
+ sovereign
mid-tier
The capability gap will continue narrowing through 2026-2027. The cost gap will not.
Four assignments. By role.
Implement multi-model routing as default architecture.
Route top-of-pyramid hard workloads to Anthropic Opus 4.7 / GPT-5.5 / Gemini 3.1 Pro. Production-tier to DeepSeek V4 Flash for cost or Qwen 3.6 for breadth. Self-hosting requirements to GLM-5.1 (MIT). Single-vendor commitment that was rational 18 months ago is now structurally suboptimal.
Articulate the open-weight strategy.
Status quo (closed frontier, API-only) is ceding enterprise self-hosting market share to Chinese labs at structural rate. Either release open-weight variants below flagship tier or explicitly accept the strategic position. Either is coherent. Current ambiguity is not.
Update production-cost models.
5–30× cost gap on Chinese vs. Western pricing is structural and will compress Western lab gross margins on production-tier workloads through 2027. Anthropic’s S-1 disclosure and OpenAI’s eventual S-1 will need to address this as forward-looking risk. 2024 margin levels are not durable.
Decontaminated benchmarks remain cleanest signal.
“China has caught up” narrative is supported by some benchmarks and contradicted by others. Genuine generalization gap remains where Chinese labs lag most. Future benchmarks should explicitly target generalization to genuinely unseen tasks, where the Western frontier advantage is most durable.
Implications of China’s Rapid AI Model Deployments
This wave of Chinese model releases indicates a strategic shift toward cost-effective, open-weight, and scalable AI solutions, which could alter deployment economics globally. While the US retains superiority in the most challenging generalization tasks, China’s advancements in agent orchestration, licensing openness, and sovereign silicon validation position it as a formidable competitor in the AI ecosystem. This development may accelerate China’s influence over AI infrastructure and applications, impacting global AI supply chains and innovation trajectories.

Dual Edge TPU PCIe Adapter for Two Coral M.2 Accelerator Cards,PCIe Gen3 x4 to 4X Gen2 x1 Lane Splitter with Heatsink,AI Edge Computing
- AI Acceleration Powerhouse: Dual-TPU machine learning workstation
- Future-Proof Design: Expandable for growing AI projects
- Developer Friendly: Optimized for TensorFlow Lite and edge AI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Recent Trends in Chinese AI Model Development
Since early 2025, Chinese labs have increasingly focused on frontier AI models, initially characterized by a long tail of smaller models. The April 2026 launch wave represents a coordinated effort across five labs, each leveraging different strategies—ranging from high-scale agent orchestration (Moonshot) to open licensing (Z.ai and Alibaba). This pattern reflects a deliberate move to establish a multi-vendor ecosystem capable of competing with US giants like OpenAI and Anthropic, especially in cost and deployment scale. Prior to this, Chinese models primarily lagged in capability benchmarks but excelled in licensing openness and silicon independence, which are now translating into tangible capability gains.
“GLM-5.1’s MIT license and training on Huawei Ascend hardware demonstrate China’s capability to develop frontier models without reliance on Nvidia hardware.”
— Z.ai spokesperson
Unresolved Questions About Long-Term Impact
It remains unclear how sustained Chinese capability will be relative to US leaders in the most complex, generalizable AI tasks. The true performance of models like GLM-5.1 against top US benchmarks is still under independent verification. Additionally, the long-term economic and strategic implications of China’s open licensing and sovereign silicon focus are still emerging, and the global response remains uncertain.
Next Steps in Monitoring Chinese AI Ecosystem Growth
Further independent benchmarking of Chinese models will clarify their standing in top-tier tasks. Monitoring subsequent model releases, licensing strategies, and hardware developments will reveal whether China can sustain its current momentum and close the capability gap. Additionally, observing how US and Chinese ecosystems adapt to these shifts will be critical for understanding future AI deployment and innovation trajectories.
Key Questions
How do Chinese frontier models compare to US models in performance?
While models like GLM-5.1 and Kimi K2.6 show promising capabilities, independent verification of their performance against US benchmarks is still ongoing. US models currently lead in the most complex generalization tasks, but the gap is narrowing.
What advantages do Chinese models have over Western counterparts?
Chinese models benefit from open licensing, sovereign silicon validation, lower costs, and scale, enabling broader deployment and experimentation.
Will China’s focus on open-weight licensing and sovereign silicon change the global AI supply chain?
Potentially yes, as these strategies reduce dependency on US hardware and proprietary models, fostering a more diverse and resilient AI ecosystem.
Are Chinese models ready for commercial deployment at scale?
Models like DeepSeek V4 Flash demonstrate production-level cost efficiency, but widespread commercial adoption will depend on further performance validation and ecosystem readiness.
Source: ThorstenMeyerAI.com







